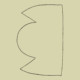
1969 veröffentlichte Eugen Gomringer schweigen, einen Klassiker der Konkreten Poesie. Dieses Schweigen, die aktive Nichthandlung, ist im Gedicht durch eine paradoxe Auslassung angezeigt, eine Atempause in der Textzeile. Denn woraus besteht schweigen, wenn nicht aus Text? Die Frage ist aber: aus welchem Text? Man könnte meinen, aus der mehrmals wiederholten, rechteckig angeordneten und schließlich in der Mitte unterbrochenen Zeichenfolge »s«, »c«, »h«, »w«, »e«, »i«, »g«, »e« und »n«.
Das ist prinzipiell richtig, wenn man den Text des Textes als ideal existierend versteht. Es ist aber konkret falsch, wenn nämlich dieser Text digital dargestellt wird und selbst wieder als Text codiert werden muss. Selbst das merkwürdig doppelte Schweigen, die Abwesenheit des Wortes »schweigen«, ist dann textlich konfiguriert. Aber weil das so ist, kann man dieses Schweigen auch hören. Warum das so ist, dazu muss ich ein bisschen ausholen.

Digitale Literatur – wenn sie nicht nur die Schilderung von Menschen sein will, die digitale Geräte verwenden – ist Literatur, die weiß, dass heute alles Text ist und es zu ihm kein Äußeres gibt. Dabei ist das keine Metapher, die als dekonstruktivistischer Leitsatz längst zur Plattitüde geworden ist. Ganz unmetaphorisch, technisch verstanden beschreibt er nämlich unsere Wirklichkeit. Die Welt im Digitalen ist eine Welt aus Text, denn jedes Bild, jeder Ton, jedes Video, ja jedes Textdokument selbst ist nichts als alphanumerisch codierte Information. Digitale Literatur wäre nun diejenige Literatur, die um diese Textlichkeit weiß und sie ernst nimmt, in sie eingreift und sie als stets potentiell literarisch versteht. Genau das war der Versuch, den ich mit Halbzeug unternommen habe, einem Band mit digitaler Lyrik, der Mitte März im Suhrkamp Verlag erschienen ist.
Digitale Literatur kann Coding verwenden, um Literatur zu produzieren, aber sie muss es nicht. In Halbzeug geht es nicht nur um die angeblich so sinistren Algorithmen. Bei der Aufregung um ihre Herrschaft – auch sie sind natürlich Text, wenn auch selbstausführender – wird jener andere Text, auf den sie angewiesen sind, gern übersehen: die Information, die Datenstruktur, ohne die jeder Algorithmus leerdrehen würde, weil er nichts zu verarbeiten hätte. Kann man sich einen Algorithmus wie ein Kochrezept vorstellen, eine Reihe von auszuführenden Regeln, dann sind Datenstrukturen die Zutaten; für den Kuchen braucht es beide. Nicht von ungefähr lautet eine inzwischen vierzig Jahre alte Definition: »Algorithmen + Datenstrukturen = Programme.«
Für Halbzeug habe ich versucht, auch Datenstrukturen literarisch werden zu lassen. Interessant an ihnen ist, dass sie ihre Identität nie in sich tragen. Diese Abhängigkeit zeigt sich schon in den fundamentalen Datenstrukturen, die in jenem Quellcode stecken, in dem ein Programm geschrieben wird. Ob das Zeichen »111« eine Zahl (etwa einen Integer) oder eine Zeichenkette (einen String) bezeichnen soll, muss in vielen Programmiersprachen erst festgelegt werden und bestimmt dann die jeweils möglichen Operationen: Verstehe ich »111« als Dezimalzahl, kann ich sie in ihre Primfaktoren zerlegen (nämlich die Zahlen 3 und 37); betrachte ich »111« als Text, kann ich seine Zeichenlänge überprüfen (was dann wiederum eine Zahl ausgibt, nämlich 3).1 Der Datentyp ist also an eine Regel gebunden, die bezeichnet, was mit den Daten angestellt werden kann, aber selbst nicht Teil der Daten ist.
Nun wäre ein Programm, das nur auf die Daten des Quellcodes angewiesen ist, sehr unflexibel. Daher beziehen Programme ihre Daten oft von außen, manchmal aus Nutzerabfragen, meistens aber aus anderen Dateien. Die Information, die eine Datei enthält, wird dann dem im Quellcode formulierten Auslesealgorithmus übergeben und von ihm verarbeitet. Hier wiederholt sich das Verhältnis von Datenstruktur zu Algorithmus, von Zeichen zu Typ: Die Ausleseregel, die entscheidet, wie mit den Daten einer Datei umgegangen werden soll – beschreiben sie ein Bild oder ein Textdokument? –, gehört nicht zur Datei, sondern zum die Datei interpretierenden Algorithmus. So gibt es zwei Texte: Einen, der liest, und einen, der gelesen wird; dieser erst gibt jenem seine Gestalt.
![]()
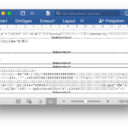
Oft begnügt sich ein Programm mit der Dateiendung, um zu entscheiden, was eine Datei darstellt. Oben links ist ein Scan von Gomringers Gedicht zu sehen, der als JPEG-Datei gespeichert ist. Ich habe es aber auch in Word abgetippt und in Microsofts DOCX-Format abgespeichert (oben rechts). Je nachdem, ob die Dateiendung von schweigen nun ».jpg« oder ».docx« lautet – beide enthalten den »idealen« Text des Gedichtes –, wird die Datei auf meinem Computer von der MacOS-Vorschau oder in Word gelesen. Was passiert aber, wenn ich die Dateiendungen vertausche? Word beschwert sich zunächst, lässt mich aber die JPEG-Datei doch öffnen:
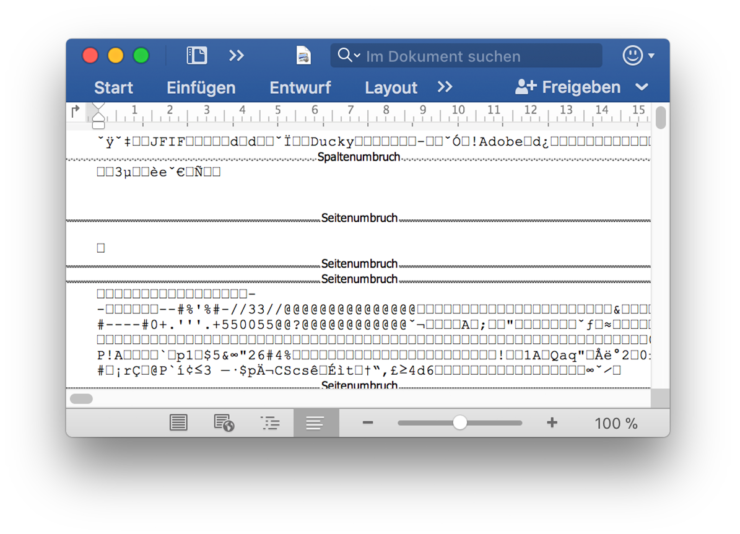
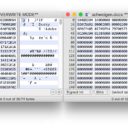
Was ich hier sehe, ist der Nachweis, dass auch Bilder Text sind, der sich wieder lesen und, als Datei, öffnen lässt – und gleichzeitig, dass auch Text wieder Text ist. Denn das Zeichenwirrwarr zeigt keinen tatsächlichen »Code«, ist also nicht die Informationsart, in der das Bildformat geschrieben wurde, sondern selbst die Interpretation eines »tieferen« Textes, der Binärdatei des JPEGs.2 Die Informationen aus Binärdateien können zufällig den Zuordnungen entsprechen, mit denen eine Ausleseregel aus Dateiinhalten mittels festgelegter Zeichensätze Text darstellt. Nicht alle Bytes der Datei entsprechen dabei der Ausleseregel, die Word vorschlägt (MacOS Roman, einem erweiterten ASCII-Zeichensatz); in einem Hex-Editor, der die Bytes der Binärdatei als Folge von Hexadezimalzahlen anzeigt, kann ich auch die unsichtbar gebliebenen Zeichen sehen (linkes Fenster):
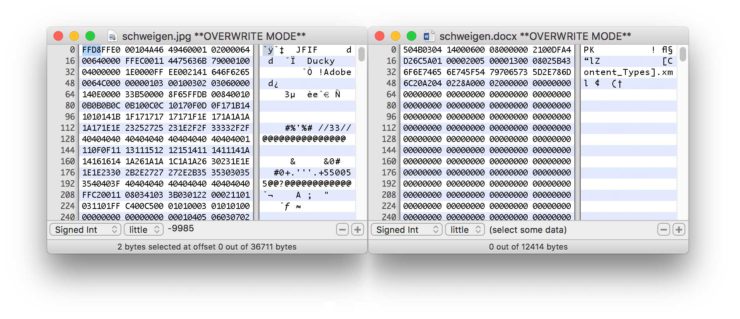
Text ist Text: Die ersten zwei Bytes der Bilddatei, »FF D8«, bezeichnen die hexadezimale Schreibweise für die Dezimalzahlen 255 und 216. Im MacOS-Roman-Zeichensatz entspricht die Position 255 dem Zeichen »ˇ« und die Position 216 dem Zeichen »ÿ«. Aber diese Übersetzungsregel wurde der Datei vom Programm aufgezwungen; ein Programm, das den JPEG-Codec beherrscht, erkennt »FF D8« gar nicht als Elemente dieses Zeichensatzes, sondern als »Magische Zahl«, einen Marker, der eine Datei als JPEG kennzeichnet, so dass – wie etwa in Unix – auch ohne die Dateiendung klar ist, welche Ausleseregel angewandt werden muss. Das heißt aber auch, dass jeder im Digitalen dargestellte Text selbst, eine Ebene tiefer, aus hexadezimalem Text besteht, der immer bereits durch eine Regel interpretiert werden muss, um für uns lesbar zu werden. In Fall des JPEG lassen sich etwa »Ducky« (44 75 63 6B) und »Adobe« (41 64 6F 62 65) als ASCII-codierte Wörter erkennen (und zeigen an, dass das JPEG mit Adobe Photoshops »Save for Web«-Funktion gespeichert wurde). Und die DOCX-Datei (oben rechts) erscheint voller Text, der nicht mit dem Inhaltstext des Dokuments identisch ist; »schweigen« verbirgt sich hier in der Encodierung des Word-Formats. Auf dieser Ebene, der bloßen Binärdatei, sehen Bild und Text gleich aus. Es kommt darauf an, wie man sie versteht.
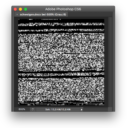
Das Spiel lässt sich umkehren, die Word-Datei als Bild öffnen. Auch dazu muss Photoshop überredet werden, indem man die Datei als raw data importiert, als unkomprimierte Rohdaten. Die Bytes der Word-Datei werden dann in Grauwerte umgesetzt. So sieht die Word-Datei »schweigen.docx« als Bild aus:
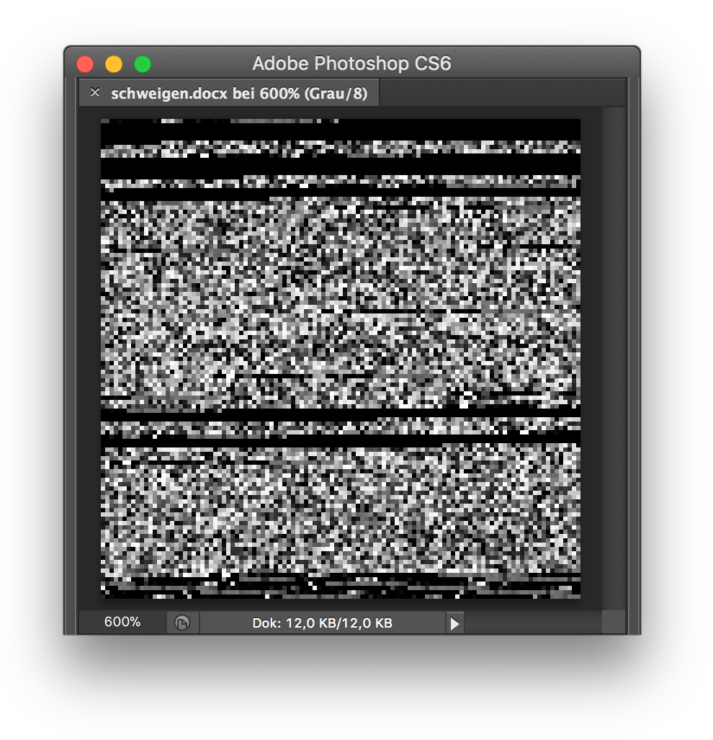
In beiden Fällen ändert sich nicht der jeweilige Urtext – die in der Datei gespeicherte Information bleibt identisch –, sondern nur die Ausleseregel, die diese Information interpretiert. Dass alles Text ist, heißt genau das: Ein Bild kann gelesen werden wie ein Text, ein Textdokument betrachtet werden wie ein Bild, nur durch Änderung des unterstellten Codecs, der Ausleseregel. Und beide, Text und Bild, können schließlich auch gehört werden.
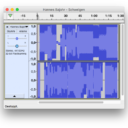
Für schweigen, meine Transcodierung von Gomringers Gedicht, habe ich die beiden Dateien »schweigen.docx« und »schweigen.jpg« im kostenlosen Audioeditor Audacity geöffnet. Wie Photoshop kann auch Audacity raw data öffnen. Gedacht ist diese Funktion, um beschädigte oder unvollständige Dateien wiederherzustellen, in denen die Information über den Dateityp verlorengegangen ist. Audacity fordert daher dazu auf, den Codec selbst zu bestimmen, samt einiger Parameter. Ich wähle als Codec GSM 6.10, das Format für Audiodatenkompression im Mobilfunk, und die Abtastrate 2000 Hz für das Bild sowie 1540 Hz für die Textdatei.3 Ich lege die Textdatei auf die linke, die Bilddatei auf die rechte Spur:
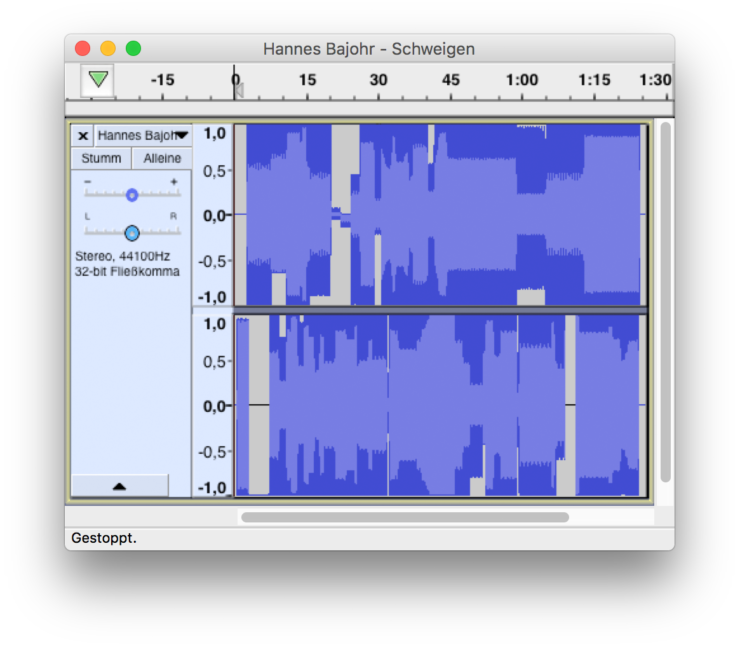
Jetzt kann ich dieses Arrangement als Stereo-MP3 abspeichern. Spiele ich es ab, höre ich das Rumpeln und Rauschen jener Texte, die Gomringers Text als Bild- und Textdokument sind, verstanden durch die Ausleseregel des Audio-Codecs. Schweigen ist nun hörbar. Ich lege die MP3 auf meinem Server ab und lasse eine Kurz-URL dazu erstellen, aus der ich Gomringers »Konstellation« nachbaue.
Sie sehen gerade einen Platzhalterinhalt von SoundCloud. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
So steht »schweigen« nun in Halbzeug. Ein Text, der auf die Texte interpretierende Datei verweist, die selbst wieder Text ist. Es ist eben alles Text im Digitalen. Und zwar ganz wortwörtlich.4